


Shapeshifting Media & Collaboration
How is software changing?

In the previous post about AI interfaces, I talked about how we can transform media by turning it into higher-level concepts and then reconstruct it as other media types.

It then expands the idea into how we can construct interfaces that mirror mental models of how people think about media. What emotion does this piece of text have? How formal is it? How old is the character in this image?
We have plenty of examples of this in how we work with media today. The three-act structure in screen writing?
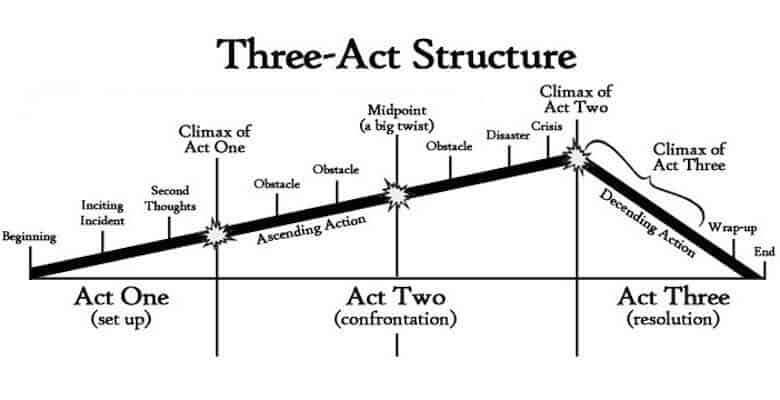
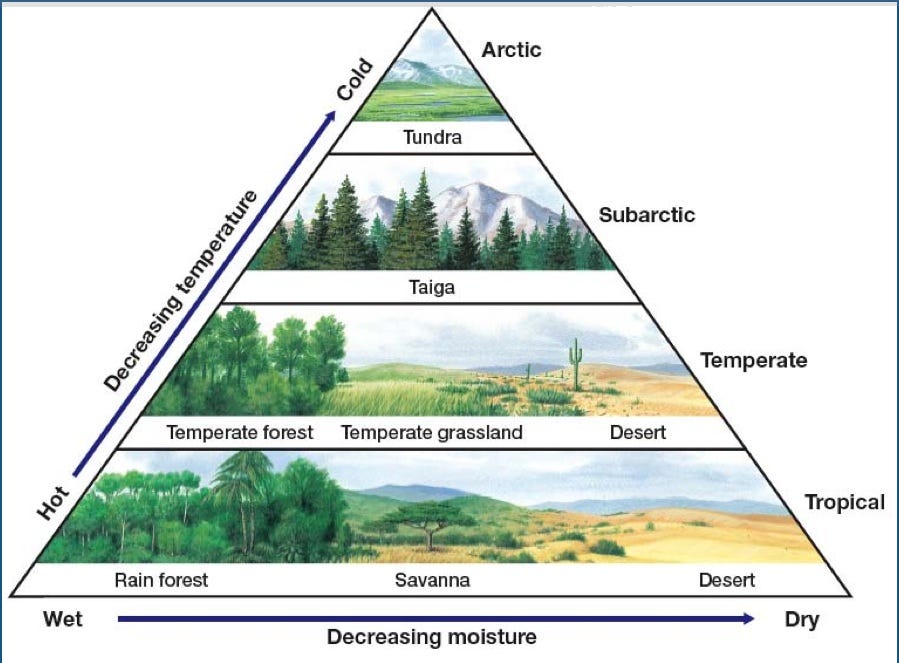
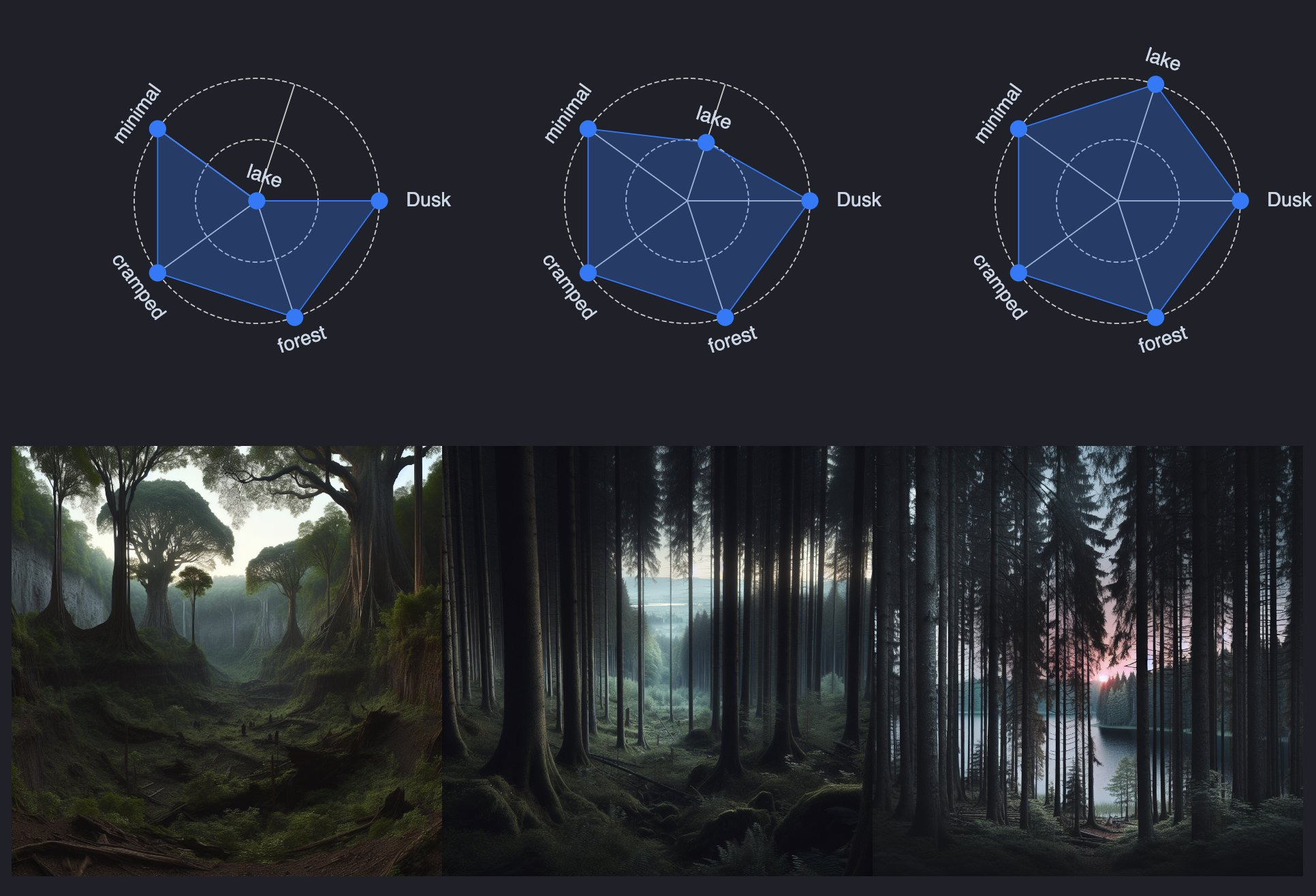
Or models of biomes?
Characters who follow an arc from “good” to “bad” will often go from lighter, brighter colors to wearing darker, more menacing colors. What if our tools surfaced this?
How does the creative process & how we collaborate with others change when we lean into this?
Structure & Details
AI tools can be thought of as a form of auto-complete, something that can fill in the gaps and add detail to messy, loose structure. Creating tools to control the structure is becoming increasingly important for controlling the outputs of generative systems.
It’s also much easier to create algorithms to control messy / loose structure than it is to control fully fleshed out media.
Here I’ve segmented a series of images and turned them into masks. I’ve then generated signed distance fields from those masks which allows me to morph between the silhouettes.

I go from dinosaur to chicken, vampire to bat & then man to ball.
Set theory have many tools that can help control the structure of form as well. Union, intersection, difference, symmetric difference, etc.
Below I collaborated with Yondon Fu to feed these masks into Feature Lab & then interpolated between the properties “Dinosaur” and “Chicken”, to create an Animorphs like animation.

It feels like there’s a more general idea here that procedural systems are great at generating structure which can then be fed into generative systems to create details.
Below I’ve used Perlin Noise to generate mountains and lakes and fed it into Stable Diffusion as a depth map to control the shape of an image.
Here’s the output:

But it’s not just about generating structure procedurally and using that to inform details, it’s also about interpreting media and being able to pull structure or details from them and use that to inform generation.
Below I’ve generated normal maps for an image, used that to segment the image, then I’ve fed the segmented floor into generative AI to create a tillable texture of the same material.
Here’s the texture:

We can push this idea of deconstructing media further though. Generative images usually just give you a finished image as an output. What would a workflow look like that deconstructs that finished image into smaller pieces that can be manipulated like layers in tools such as Photoshop?
Below I’ve segmented an image generated in Midjourney using Segment Anything, then I’ve used color thief to get the dominant color in the original image for each segmented region and re-colored it. This is the base layer, then I’ve generated a normal & depth map & used them to inform lighting in the scene.
The final step was pulling out the lighting from the original image to generate an albedo map which can be used to inform the texture.

As you can see, some of the detail of the final rendering was lost, but it’s getting close to a workflow that gives artists much more creative control of the final rendering.
What makes it even more interesting is that when you segment these different objects, it would make it much easier to compose multiple objects into a single scene since they would all have consistent lighting.
Now the deconstructed image above is becoming quite similar to a 3D scene, what if instead we were to carve the depth of an image into a volumetric space to create a 3D representation of that?
We can also morph between these volumetric forms using 3D signed distance fields.
What’s potentially most interesting about these forms is that they allow us to construct simulations, visual representations of ideas that can be fed into vision api’s for controlling other kinds of media like text generation. We don’t even need to surface these simulations to the end user.
I think about it like the internal visualisations that most humans have when they are thinking about ideas.
Does modelling information as simulations give us a much higher density of information to work with when doing transformations across media? How does this change the UX patterns for how we control text generation?


Folk Practices & collaboration
As a programmer, I’ll often use version control software like Git, but there’s a huge learning curve for it & it’s not very intuitive when you first encounter it.
Even for people who’ve been using these tools for a long time, there are aspects of the workflow such as merging which can be incredibly confusing.
This is an example of asynchronous collaboration software, it allows us to work independently and then come together when we’re ready.
We then have synchronous solutions such as operational-transform (OT), conflict-free replicated data-types (CRDT’s) or in simpler terms, software like Google Docs, Figma or Notion. This kind of software allows us to work in real-time with other people & have varying support for offline workflows.

Now, these kinds of tools aren’t just useful for working with others - I’ll often write something in a Google Doc just so that I have access to it across all of my devices.
Version control software like Git allows me to try things, save them as checkpoints and if I’m not happy with them, revert back to previous points in time.
But we also have folk practices for light-weight version control such as screenshots, copy/paste, duplicating files & layers.
You’ll often see artists with a folder full of “final001.png”, “final002.png”, etc.

These are all examples of snapshots and branching. we don't have the equivalent for light-weight merging.
Auto-merging solutions in CRDTs get us part of the way there, but the way we think about user intent and merging is still too low-level.
In a text or list CRDT, we model the inserts and deletes and have rules for how those changes should converge.
Event sourcing also helps with this, "the user used the fill tool at this position, the image changed in this way" - but with AI we can begin to think about changes as semantic intent.
"The character got older", "The time of day changed from morning to night", etc.
It's not just about making merging simpler to reason about, these tools are making deconstruction and remixing an integrated part of the creative process.
By being able to say "I have this video but I want to pull out the color palette from another image and apply it to it" or "I want to apply the mood of this song to the composition of this image", it changes merging from being a tedious task into something fun and creative.
It goes further than this though, AI tools are a form of "predicting future intent" & so It's going to get things wrong. You want to be able to have workflows where you can seamlessly duplicate media and try things, to create many variations & rip out the properties of the ones you like for later use.

Duplicate & Merge become first-class actions in creative apps.
It feels a bit like foraging or collecting a heap of snippets, examples of ideas that you like for later recombination. The mixed-media mood-board becomes an integrated part of the creative process.
By bringing collaborative workflows closer to the solo experience of working with media, it breaks down the barrier to collaborating with others. It becomes less of a stretch to invite someone else into the space.
Technical implementation
I’m still heavily in research mode, discovering what the relationships are between different pieces of media and how they should be modelled as data-structures & collaboration primitives.
That being said, my current thoughts on how media should be represented at a data-structure level is as a causal tree of changes (kind of like a git tree), where rather than storing snapshots of media at points in time, it’s a history of operations that were applied to that media.
Each representation of media only exists from the perspective of the user at the point in time that they made the change. Each change building towards a more coherent representation of the underlying high-dimensional concepts that are being modelled.
The more intent that is baked into the history, the better that the transformations across media types can become. The history becomes the context.
Bring your own modality
People say they want to bring their own client. I want to bring my own modality. I should be able to work in the way that feels most intuitive to me & have those that I’m collaborating with not confined to those same tools or mediums.
What does the landscape of software look like when I could be drawing a diagram in tldraw whilst you’re writing code in vscode?
How do things change when I can talk to my podcast and ask it follow up questions or watch an academic paper as an animated series?