
AI Interfaces
Where are we and where are we going?

When we first invent a new technology, we’re really only just beginning to grasp how the technology works. This usually leads to really low-level implementations that aren’t super intuitive and require a lot of manual labour in order to be able to do anything with it.

As you can see in the diagram above, the progression of how we create software has gone from manually wiring plugs, to punch cards, writing assembly code, low-level memory management to high-level languages like Javascript. Now we’re starting to create software using natural language, voice or even drawing diagrams.
This kind of trend doesn’t just apply to programming, but to other media as well.
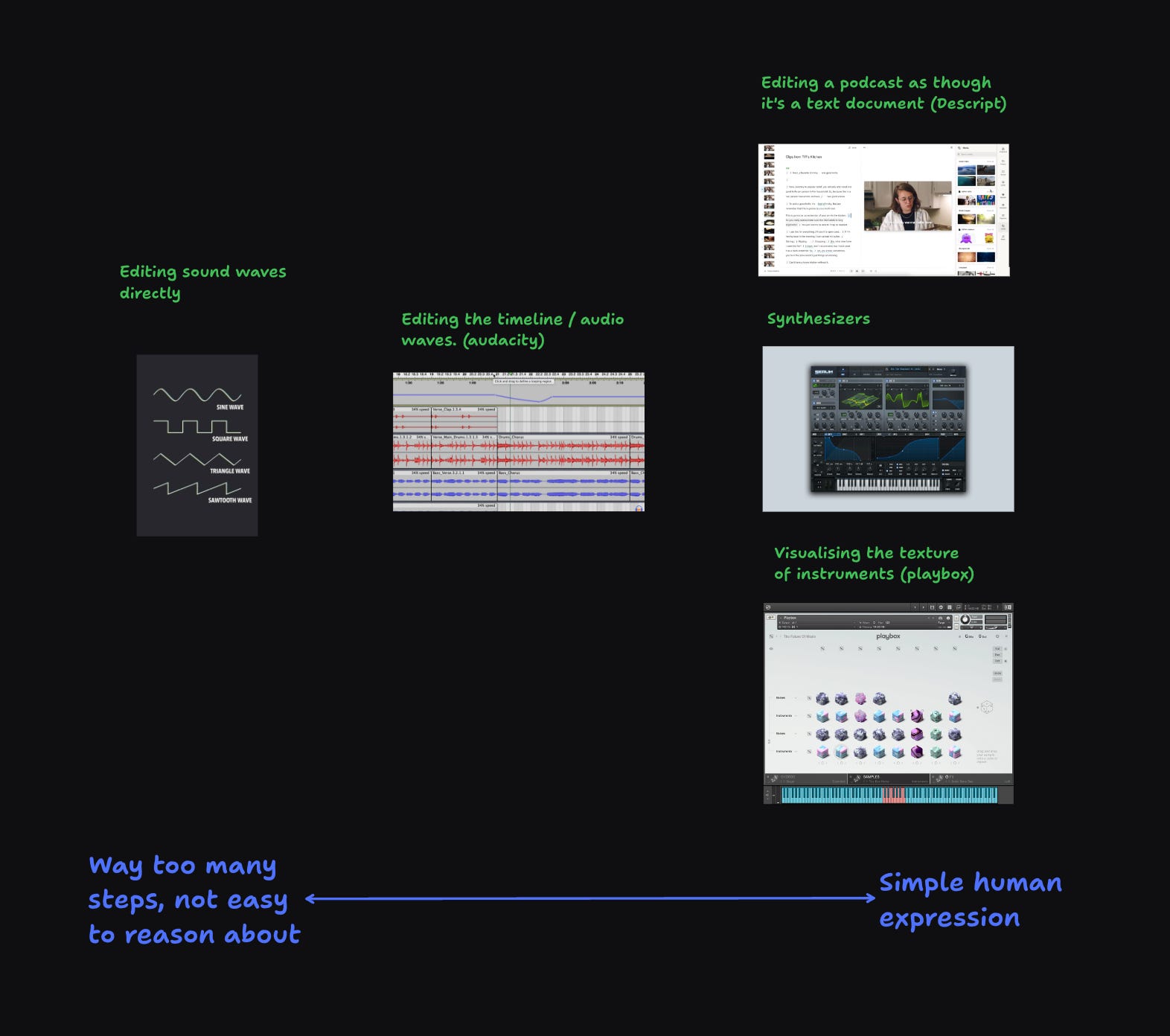
As you can see above, we’ve gone from editing sound waves directly, to having low-level tools like audacity. Now we’re starting to see much higher-level frameworks for how we think about editing audio.
From using Descript and being able to edit a podcast as though it’s a text document, to synthesisers or even how Playbox represents the properties of audio layers by displaying textures.
By moving to these simpler ways of working with media, we’re breaking down the barriers between forms.
A shared understanding of the world

As shown in the image above - Meta released a model called ImageBind which has a shared understanding of the world across media types.
If you were to search with a picture of a bird and the audio sound of a motor revving, it will find a picture of someone on a moped with birds flying around them.
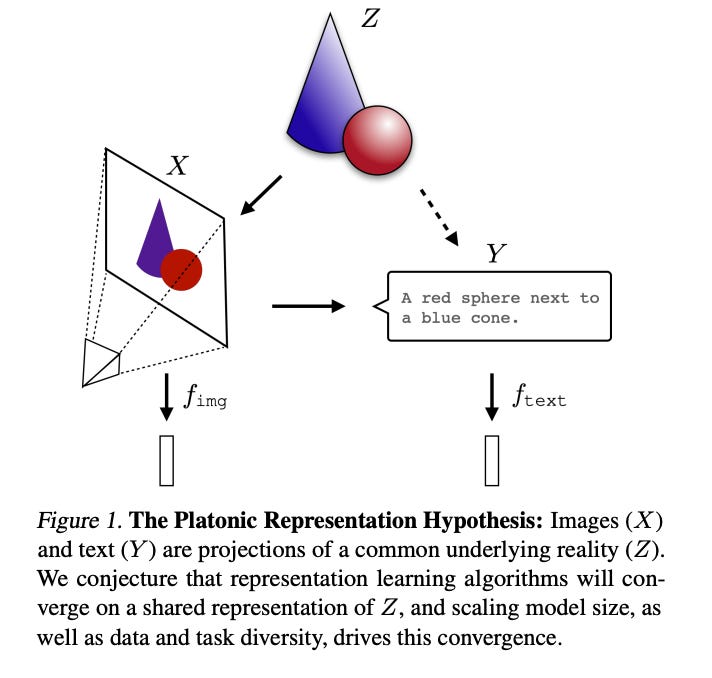
Another example of this is above, there is a picture of a red sphere next to a blue cone. The description ‘A red sphere next to a blue cone’ is actually pointing to the same underlying concept as the image.
Transforming media
By having a higher-level model of media it allows media to be transformed into different forms.

You can record audio & have it be transcribed into a text message.

Treat a screenshot as though it’s a text document by using OCR.
Convert handwritten text on a whiteboard into type.

Create 3D scenes from 2D shapes on a whiteboard.

Generate colour palettes from text prompts.

Or depth maps from source images.
Re-light scenes by converting them into pseudo 3D scenes, adding light sources to them and then collapsing them back down into images.
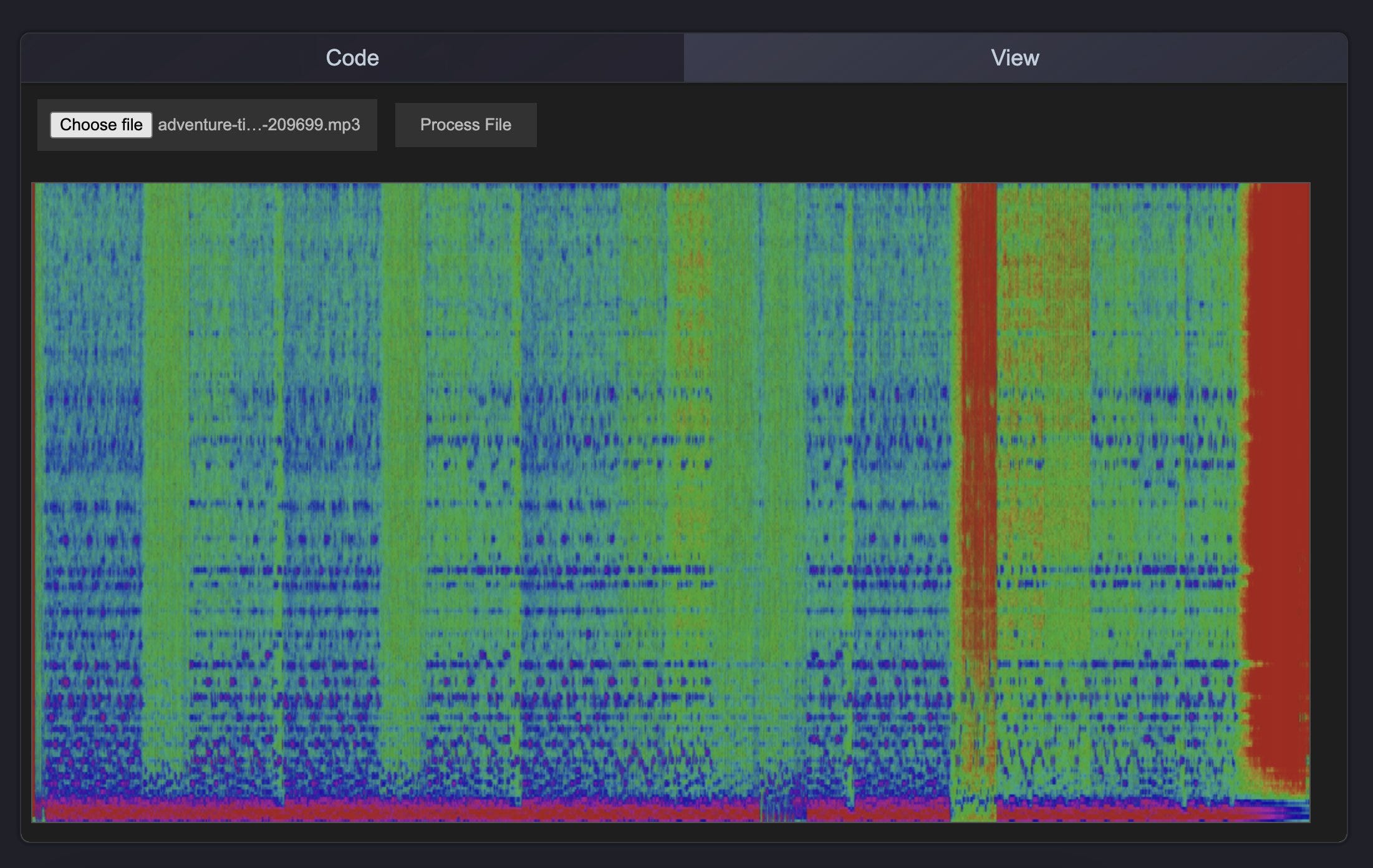
Create spectrograms from audio files.

Then use those spectrograms as inputs into image generation.
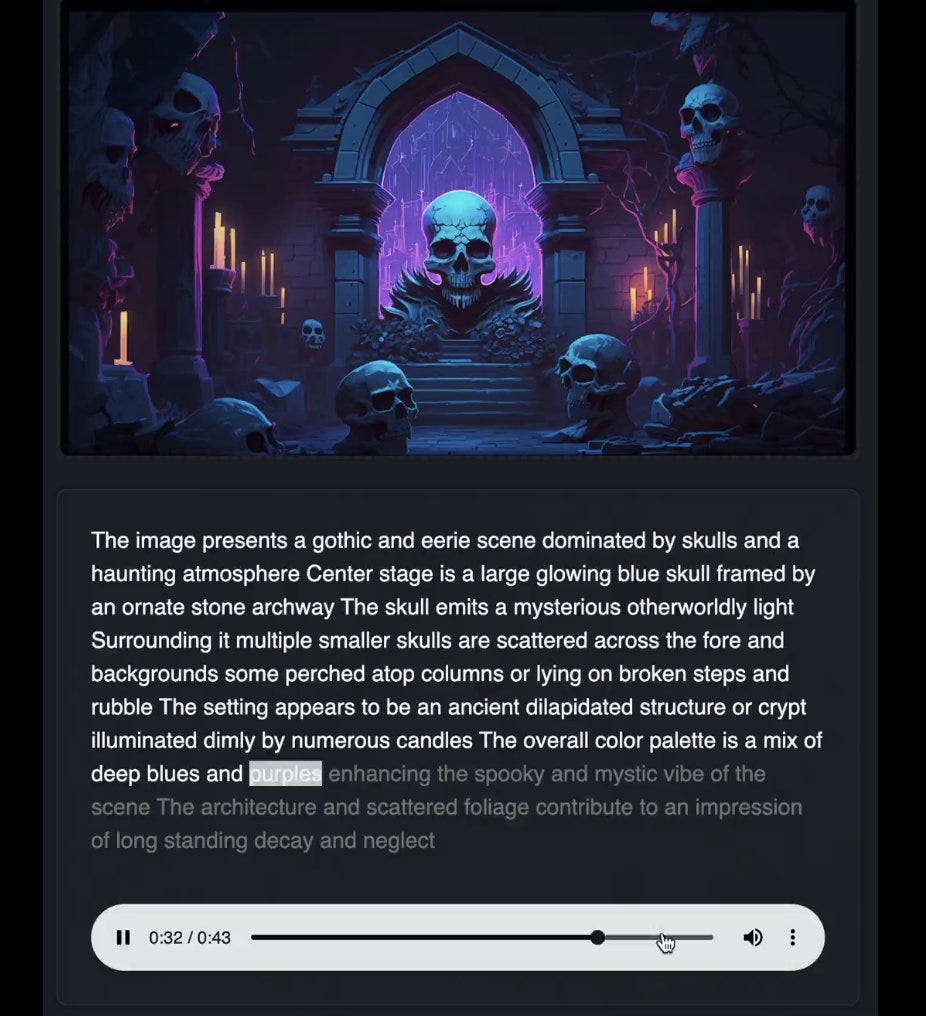
Or create multiple representations of the same piece of media across modalities to make it more accessible.
Or copy & paste descriptions of images to segment those parts of the image.
Or after segmenting characters in an image, turn them into 3D models which can be moved around the scene?
Deconstructing media
In order to be able to do faithful transformations across modalities, we need software that has an understanding of the media. Not just the pixel values or words used, but an understanding of what the objects, ideas and composition is. We need world models.
In the above video, I’ve extracted the dominant colour palette from a video.
In this video, I’ve segmented the Raccoon based on depth.
In this one, the chimp is segmented based on hue.
Here i’ve added annotations to objects in a scene using AI vision.
In this experiment I’ve used Google Gemini to ask questions about an image & it returns both the answer as well as the region of the image in which the feature is present.

Here i’ve used Meta’s Demucs model to separate a song into each of its components.

In the above experiment Anthony Morris has used prompting to analyse the attributes of a chunk of text (you can also modify their properties).
What are some examples that use deconstructed media?
By being able to segment the scene by hue & having access to its depth map, I’ve been able to create an animated pool of purple liquid. To the right is a fog effect that relies on the depth map.
These could be done with any image.
In this example I use the depth map to create a snow particle effect.
Here’s a depth based glitch effect.
Here’s the same glitch effect applied to a video.
Here’s the same glitch effect applied with its intensity mapped to curves on a timeline.
Here’s a depth of field effect.
Here’s a cloaking effect.
Creative Control
One of the big gripes with AI tooling is that for most of it - we go from some high-level idea like “I want a picture of an old man with a cane” to a fully finished piece of media.

This takes away all the autonomy from those doing the creative work and feels incredibly reductive. This is probably not what I had in mind when I prompted it.
Most tools make this a little better by generating more than one variation, but it still doesn’t really solve the problem.

We could try using AI to generate procedural systems which give us the freedom to explore variations.
BUT - what we really need is tools that allow us to think about media at a higher level, to fill in the gaps and simplify tasks, without reducing our ability to express ourselves and get our hands dirty.
We need tools that give us intuitive sense of what it will output & the ability to steer it. Text will only get us so far.
Drawing rough sketches

Scribble diffusion allows us to combine both sketches & accompanying text in order to create an output image.
Altering features in text
Both of these demo’s are built on top of the Contra model by Linus (thesephist.com).
In this video, I use a slider to transition between two pieces of text.
In this one, I isolate a feature by allowing you to enter multiple sentences & then apply that feature to a blob of text using a slider.
Altering features in images

Above is a picture of Feature Lab by Gytis - as you can see, we can change the features in a really flexible way.
For example - by increasing the presence of the fisheye lens property, the picture of the cat begins to change perspective.
Here is an example I created that caches the images before hand and allows you to explore the different emotional expressions of a character.
Or to explore a character’s age and gender?
Or to change a texture based on the season?
Or compose features into layers and in the future - use blend modes.
Or to be able to transition between hot and cold fonts?
(The above is wrong, it’s not Google Gemini - It’s actually GenType)
Or compose / decompose elements in an image into raw components?
Or explore features of a landscape.
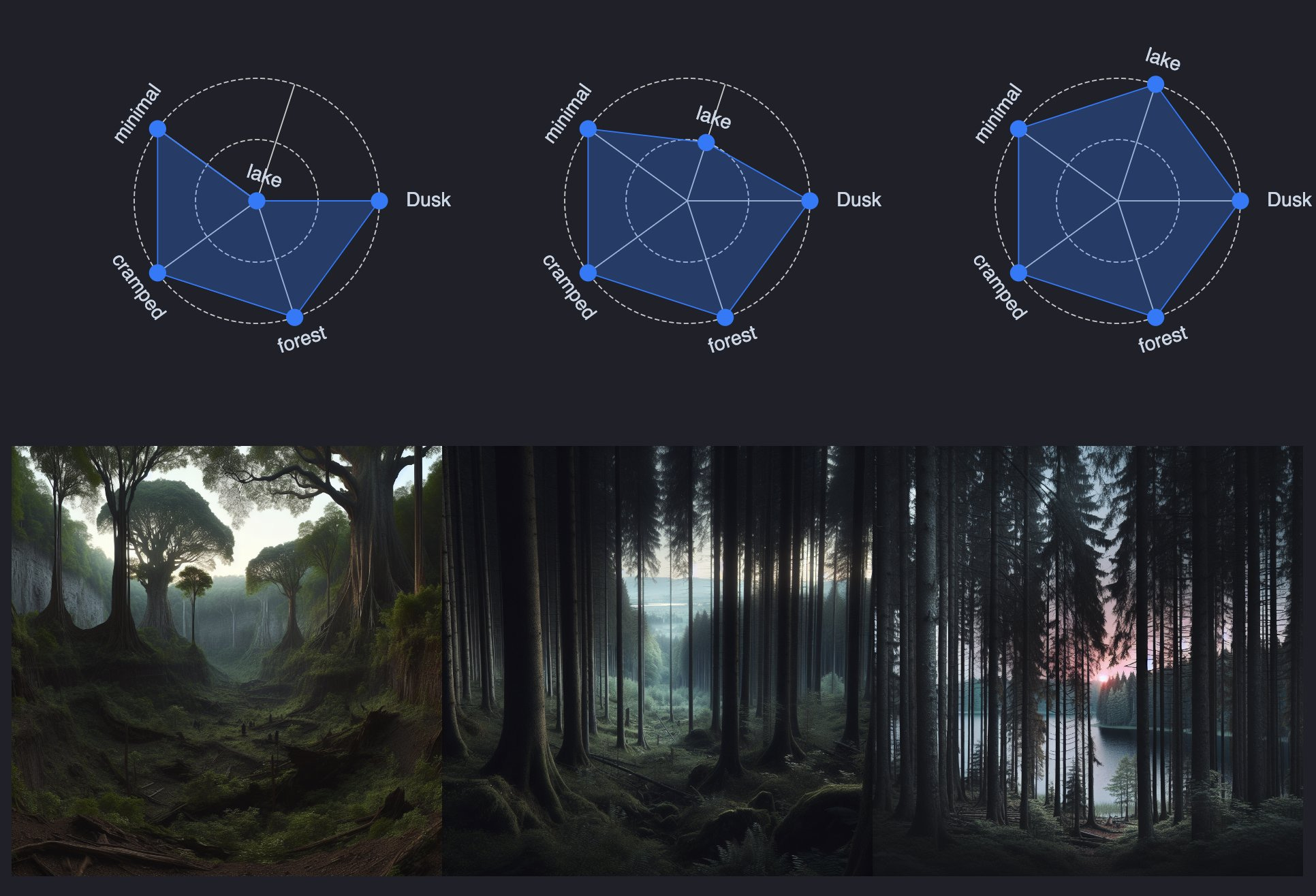
Or merge features together?

Above is a table showing the presence of different fruit in a fruit bowl, with the x axis being how decay impacts them.
Treating objects in a scene as layers?

What if I could select an object in a scene like this & then delete it? Or bring it to front?

A feature palette
What if rather than just having colour palettes, we could have feature palettes?
Portrait animation
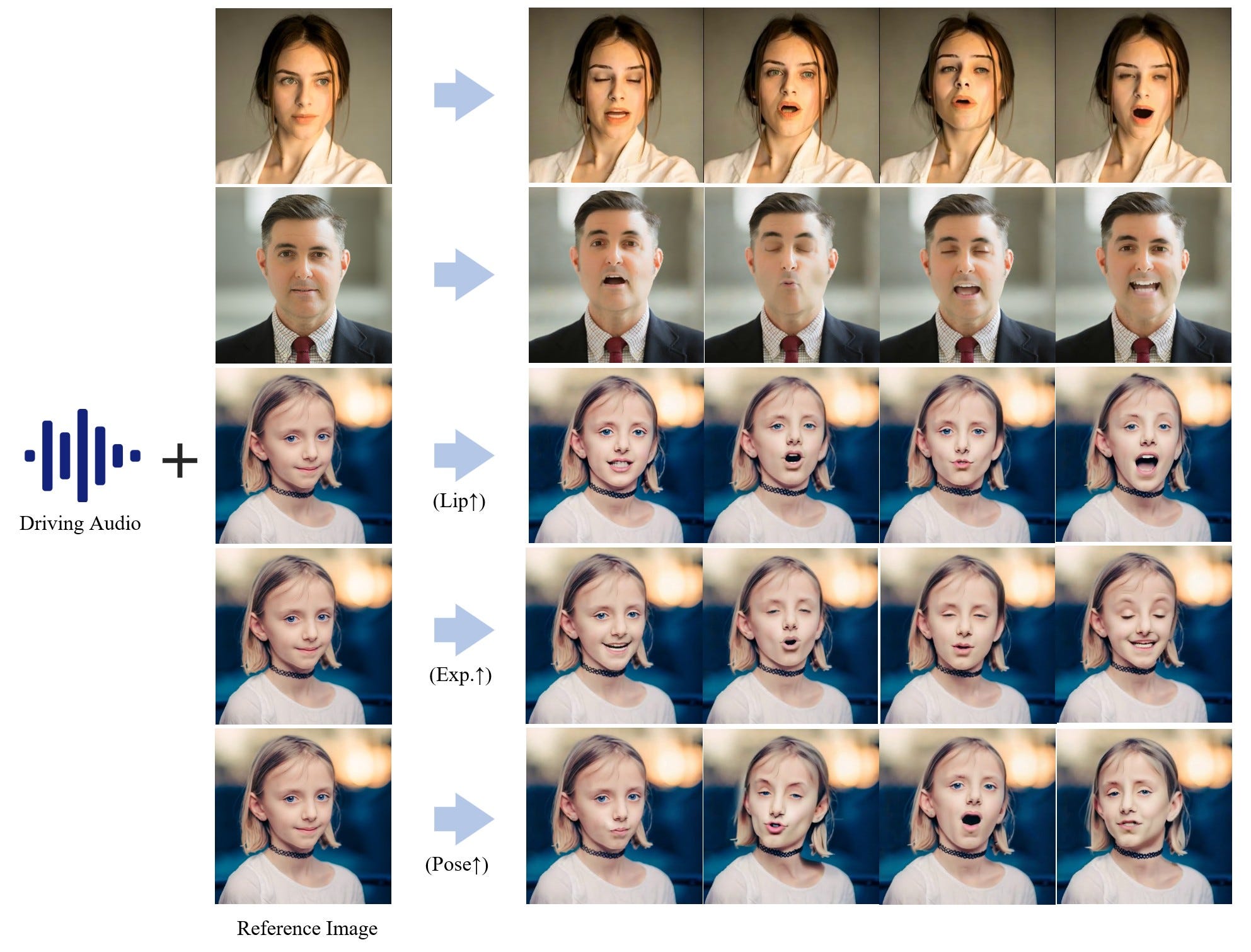
We’re also seeing tools like Hallo which allow us to supply an audio file & a reference image and it will create a video of the character talking.
Pose animations
There are also tools which allow us to edit the pose of a character and animate them.

DragGAN is another tool which allows us to control the positioning of elements within an image.
As you can see, by clicking and dragging on the mountain, we can change how tall it is.
Zoom
Once you’ve generated an image in Midjourney, you’re able to zoom out & pan. Many tools also have in painting, which allows you to select a portion of an image and re-prompt it.
By generating images at many different zoom levels I created a semantic zoom slider.
Using a start & end image and a prompt to create videos
Using Luma Labs you can generate short video clips given a start & end frame, in this example, I used the two zoom levels from before and created a video where the camera zooms out away from the character.
Motion brushes

I’d really like better video tools that allow me to express motion through brushes or arrows.

It feels much more intuitive than just using text & image prompts all the time.
Camera controls
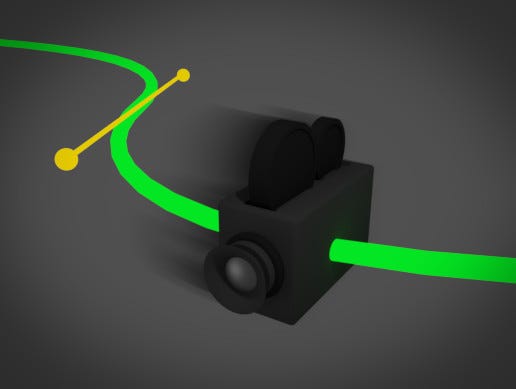
While we’re talking about video controls - what I really want is the option to be able to create a curve (spline) to control the motion and the target of the camera throughout the video.
Using masks & reference images

Above I’ve created a simple scene editor, it allows me to create shapes and move them around the scene. As you can see, each of the blocks has a different colour, this allows me to separate the blocks by colour and give those regions different prompts.

Palette transfer
By using the dominant colours detected in both images, you can transfer the palette from one image to another (or video).
What becomes possible when media is controllable at a high level like this?
Music that adapts to your heart rate as you run, fully living worlds in games where characters age, seasons change, the world erodes, etc.
(Water the plant and watch it grow)
(A simple fighting game where the characters avatar’s get more damaged and bloody as they lose health)
It allows us to scour through content at a really high level and zoom into the details as we need them. To view content through many different lenses and explore information as dynamic systems.
It allows us to express ourselves in the ways that feel most intuitive to us and consume content in the same way.
If you’re exploring similar ideas, I’d love to connect.